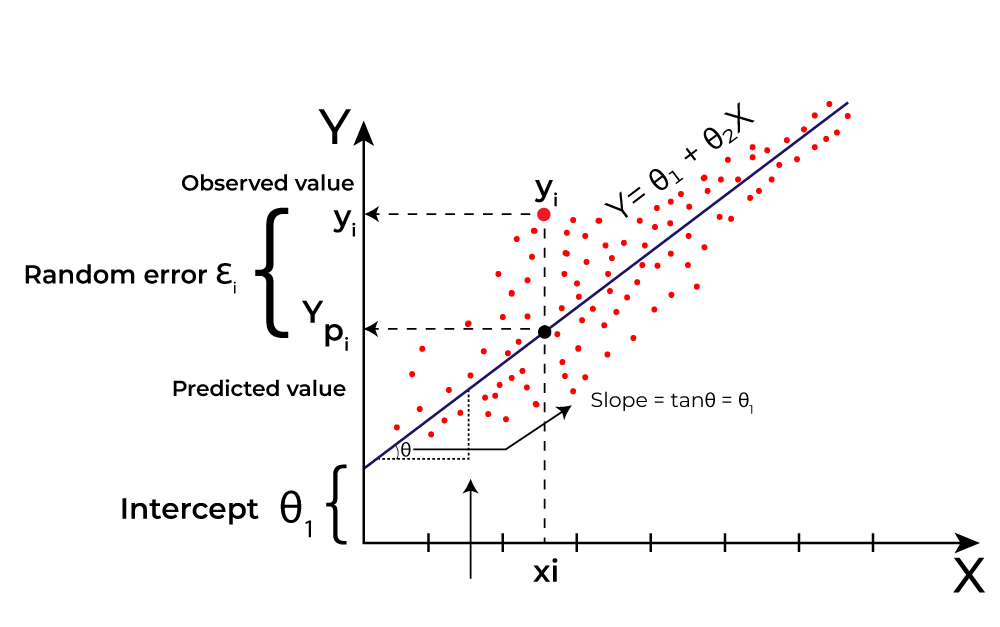
1. Line regression 1.1 Ordinary Least Squares (OLS) Perspective 1.1.1 Model Representation: The linear regression model is represented as: \hat{Y} = X

github: https://github.com/pandalabme/d2l/tree/main/exercises 1. Can we treat exhaustive search as a special type of beam search? Why or why not? We c
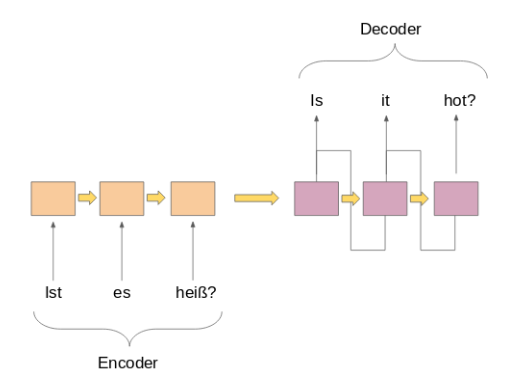
github: https://github.com/pandalabme/d2l/tree/main/exercises 1. Suppose that we use neural networks to implement the encoder–decoder architecture. Do
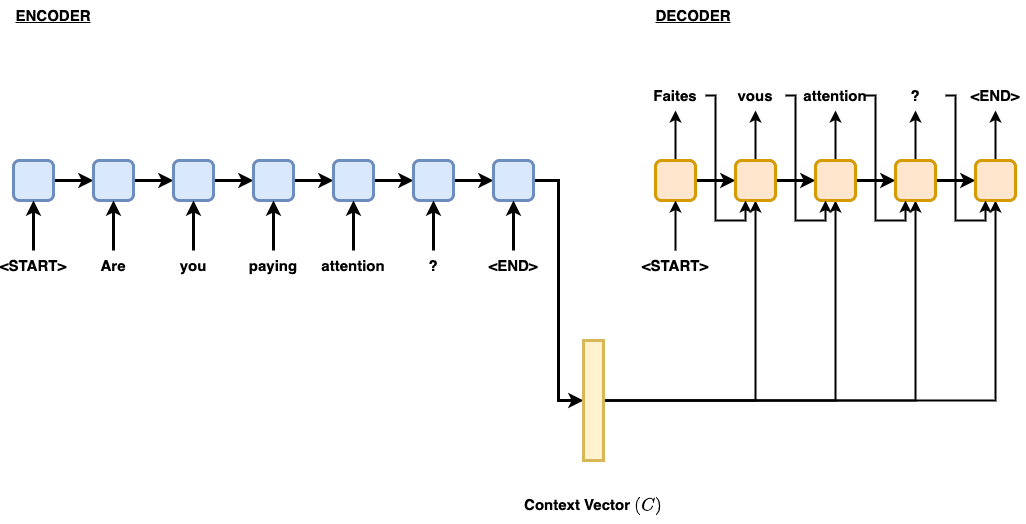
github: https://github.com/pandalabme/d2l/tree/main/exercises 1. Try different values of the max_examples argument in the _tokenize method. How does t
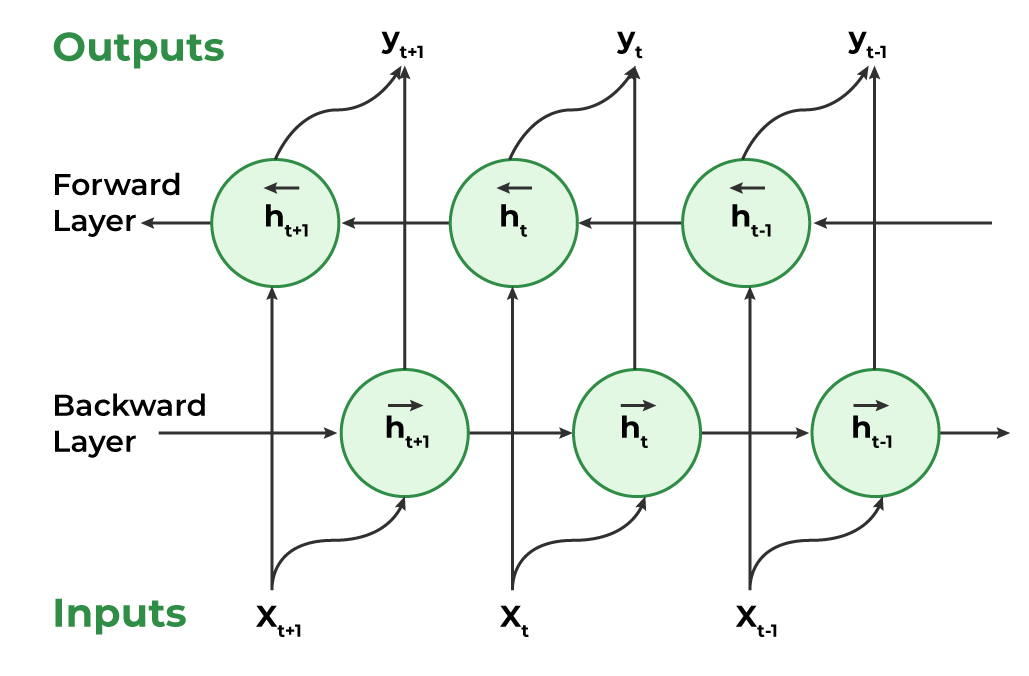
github: https://github.com/pandalabme/d2l/tree/main/exercises 1. If the different directions use a different number of hidden units, how will the shap
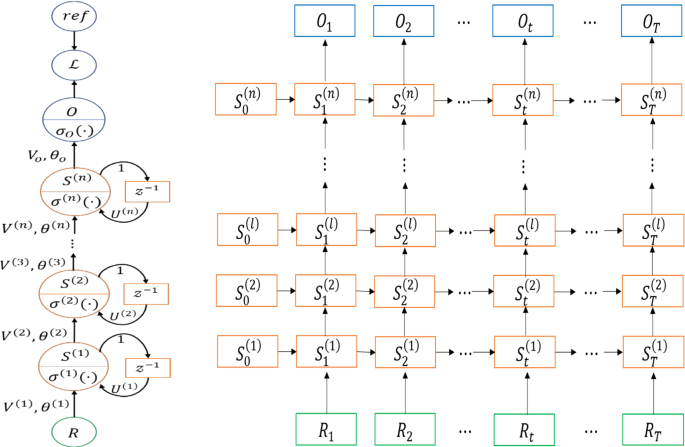
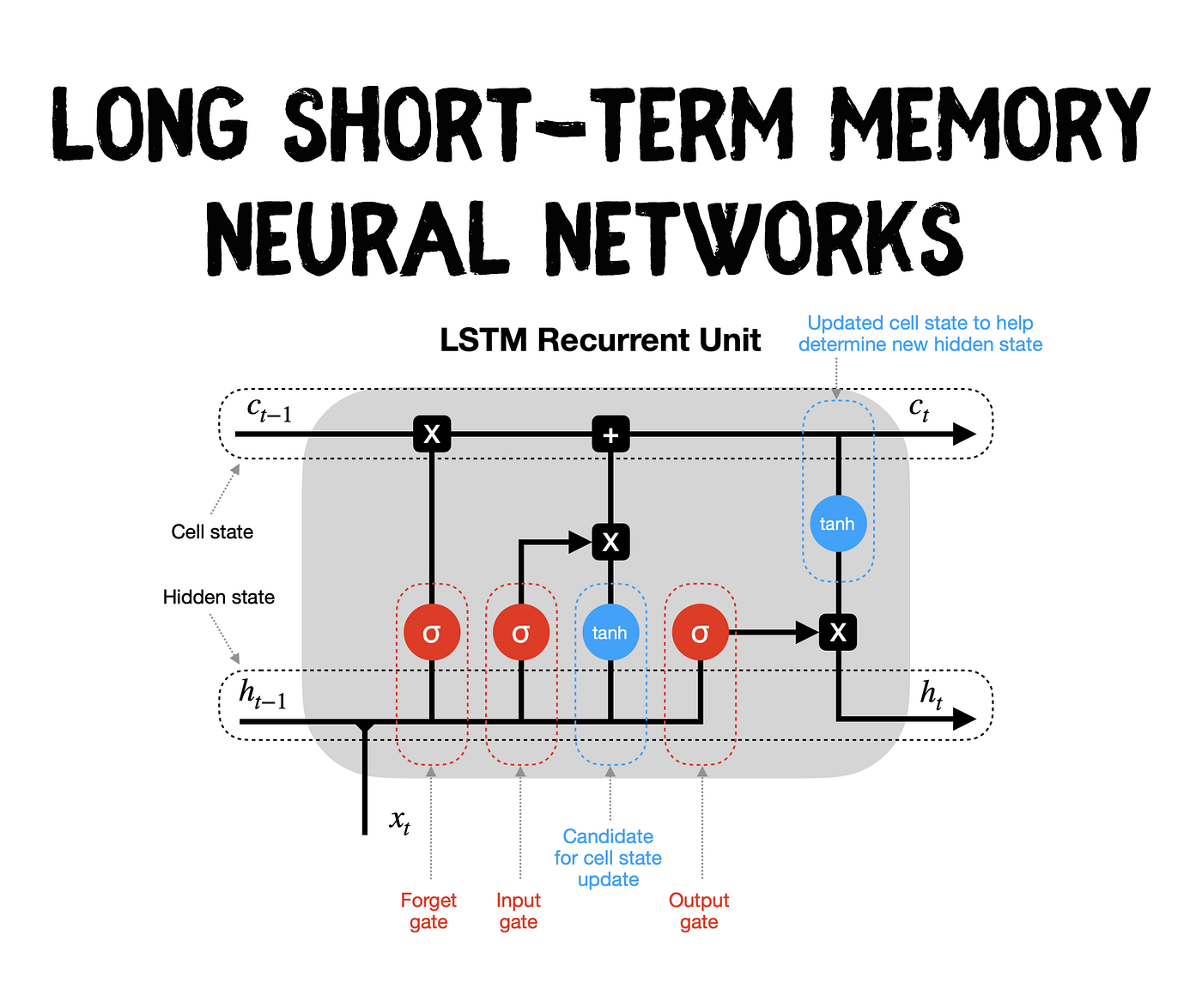
github: https://github.com/pandalabme/d2l/tree/main/exercises 1. Replace the GRU by an LSTM and compare the accuracy and training speed. import sys im
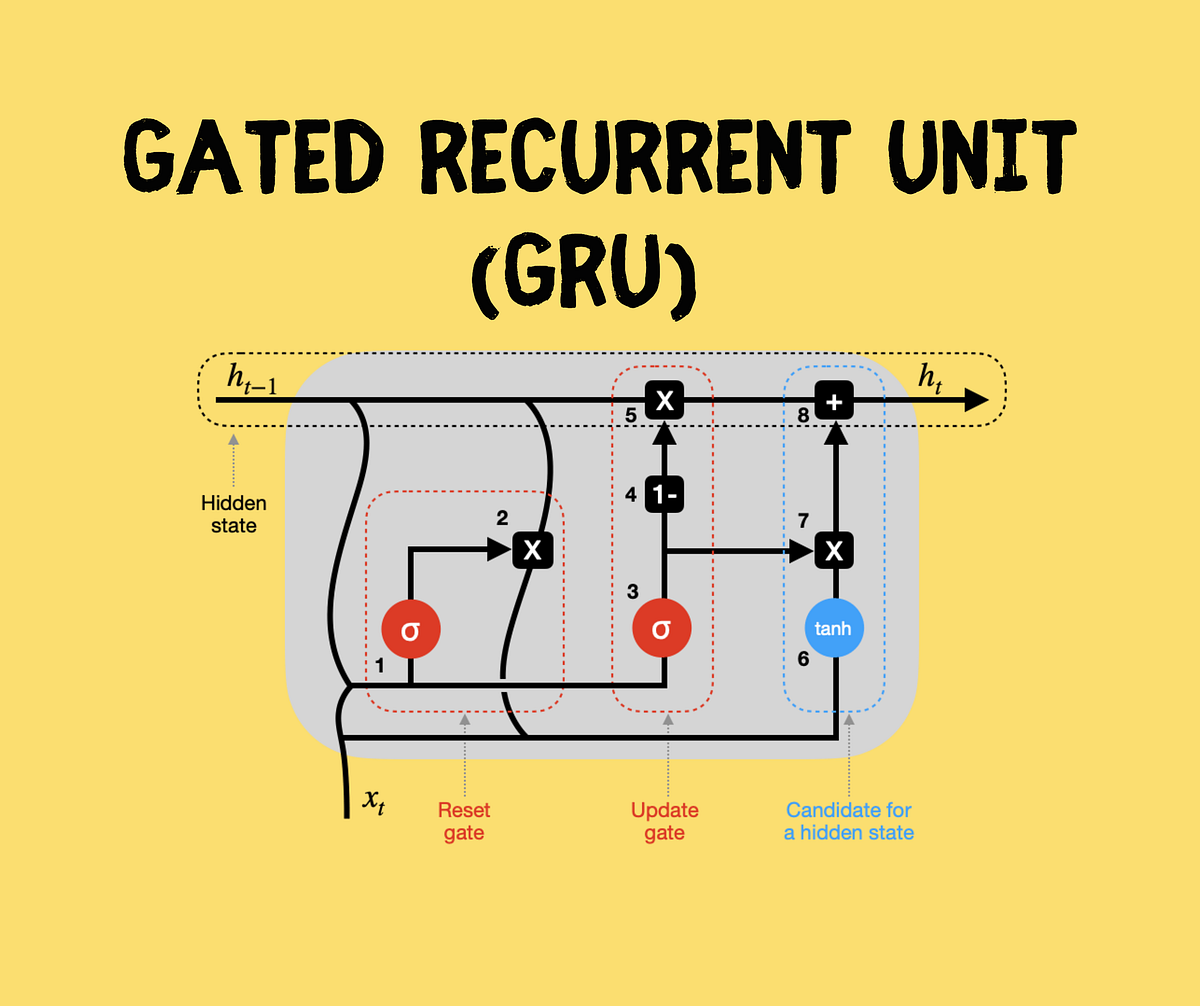
github: https://github.com/pandalabme/d2l/tree/main/exercises import sys import torch.nn as nn import torch import warnings from sklearn.model_selecti
github: https://github.com/pandalabme/d2l/tree/main/exercises 1. Assume that we only want to use the input at time step t' to predict the output at ti
github: https://github.com/pandalabme/d2l/tree/main/exercises 1. Assume that we have a symmetric matrix M\in\mathbb{R}^{n\times m}
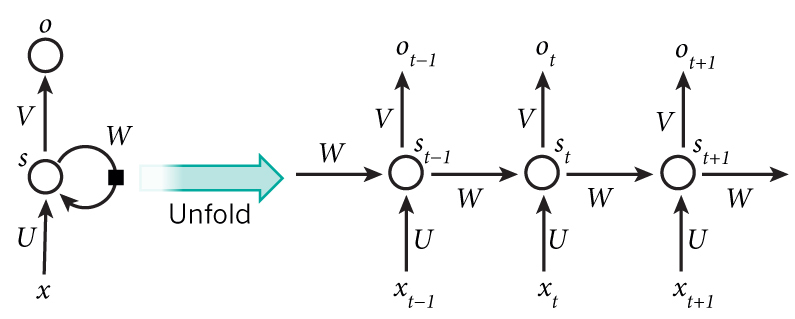
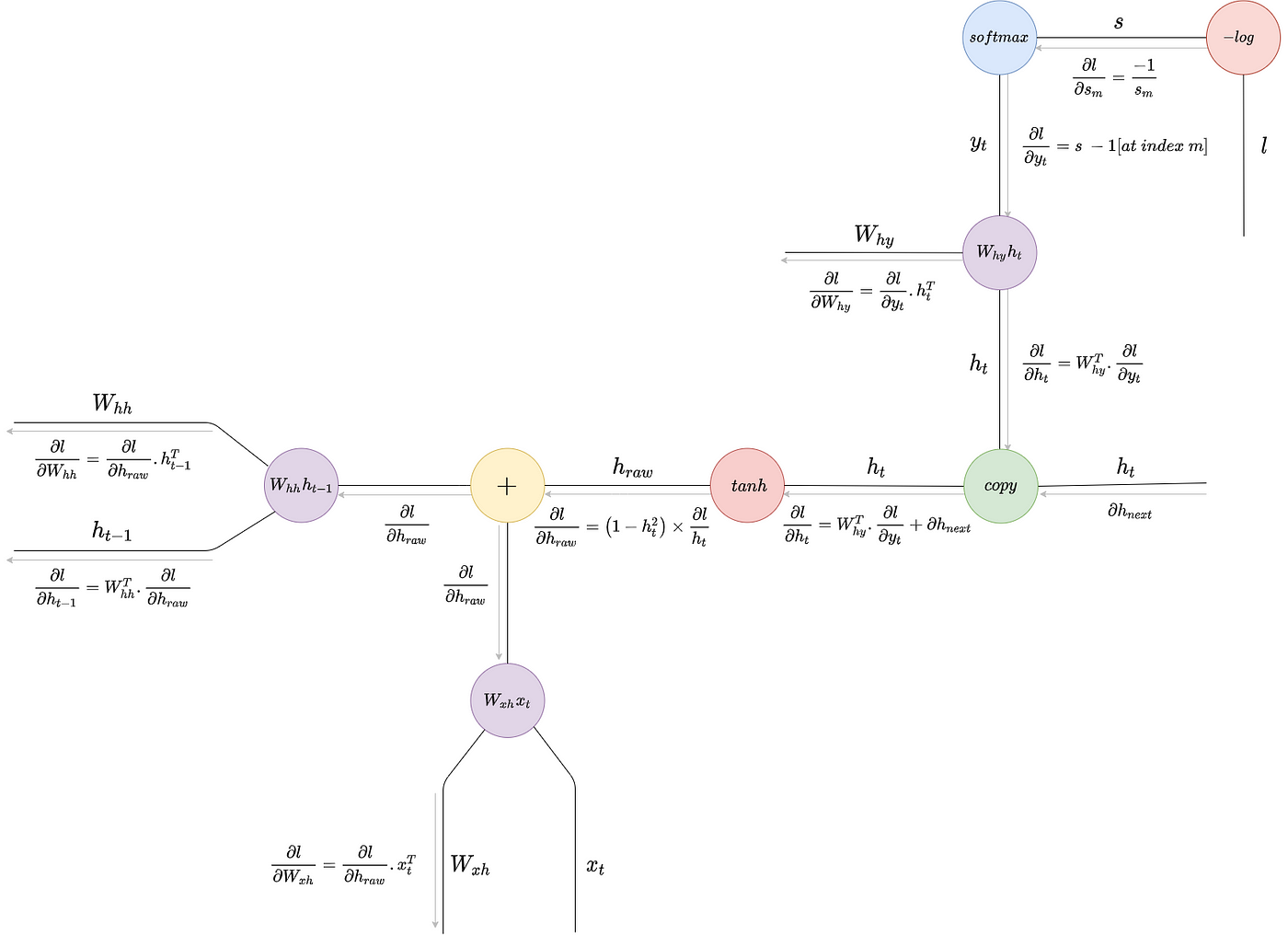
github: https://github.com/pandalabme/d2l/tree/main/exercises 1. Does the implemented language model predict the next token based on all the past toke
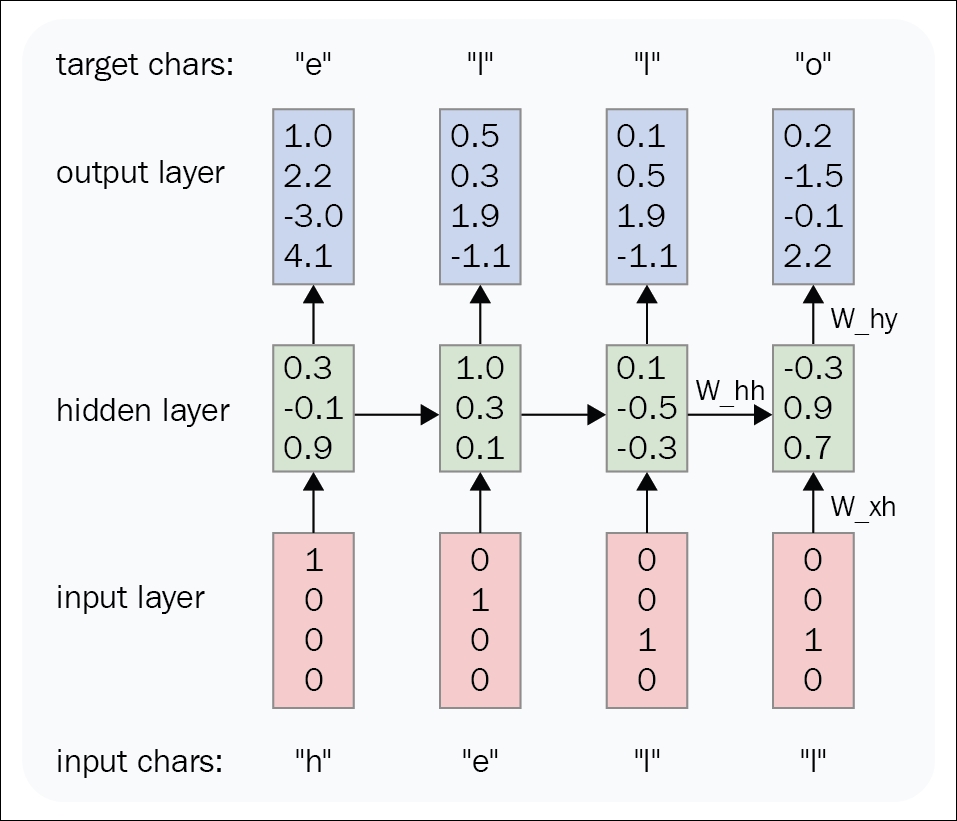
1. Can you make the RNN model overfit using the high-level APIs? Yes, you can intentionally design an RNN model to overfit using high-level APIs like