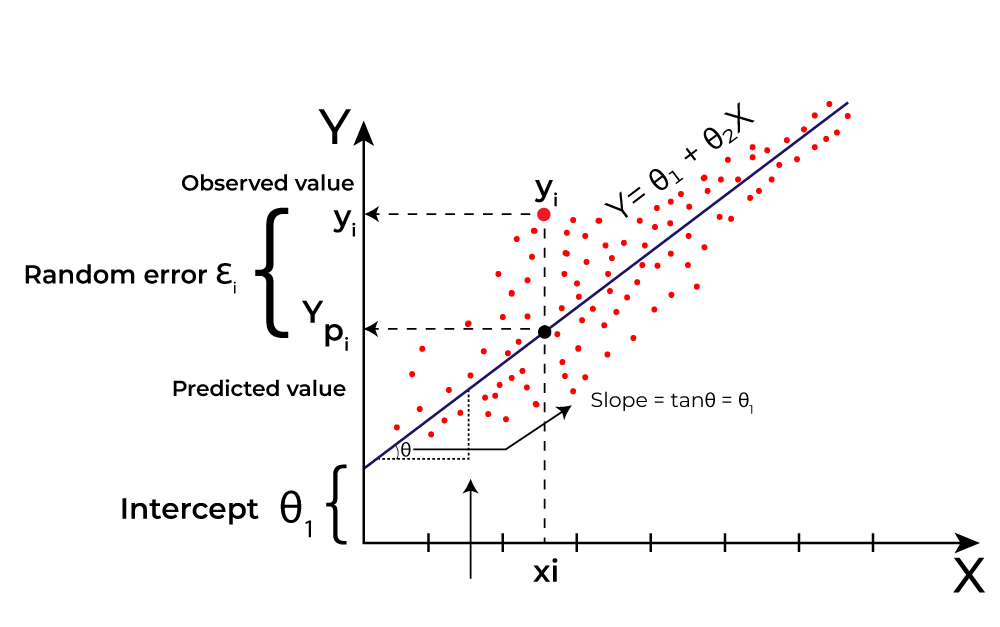
1. Line regression 1.1 Ordinary Least Squares (OLS) Perspective 1.1.1 Model Representation: The linear regression model is represented as: \hat{Y} = X
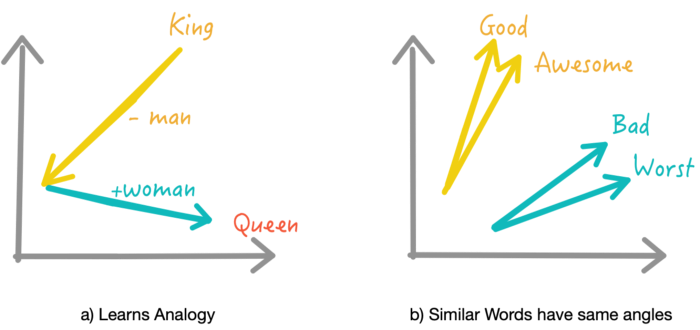
github: https://github.com/pandalabme/d2l/tree/main/exercises 1. Test the fastText results using TokenEmbedding(‘wiki.en’). import os import torch fro
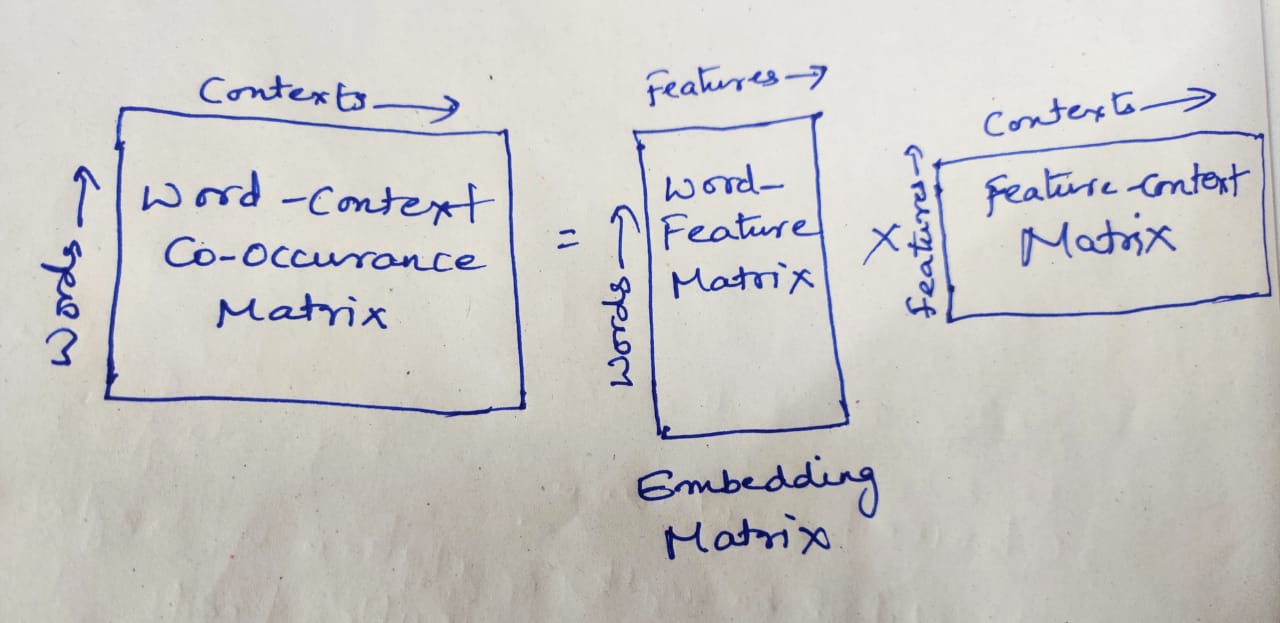
github: https://github.com/pandalabme/d2l/tree/main/exercises 1. If words w_i and w_j co-

github: https://github.com/pandalabme/d2l/tree/main/exercises 1. As an example, there are about 3\times 10^8 possible 6-grams in English. What is the
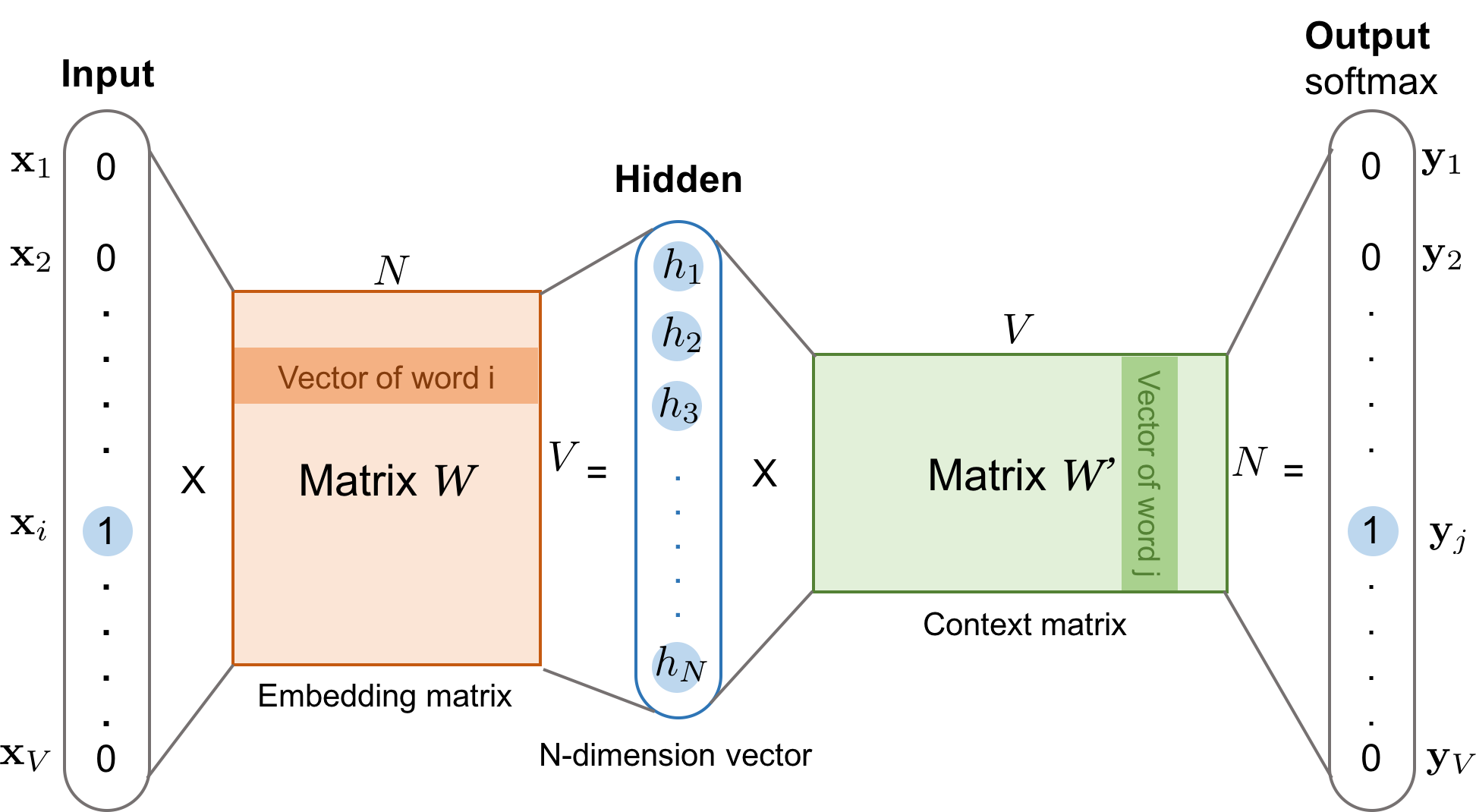
github: https://github.com/pandalabme/d2l/tree/main/exercises 1. Using the trained model, find semantically similar words for other input words. Can y
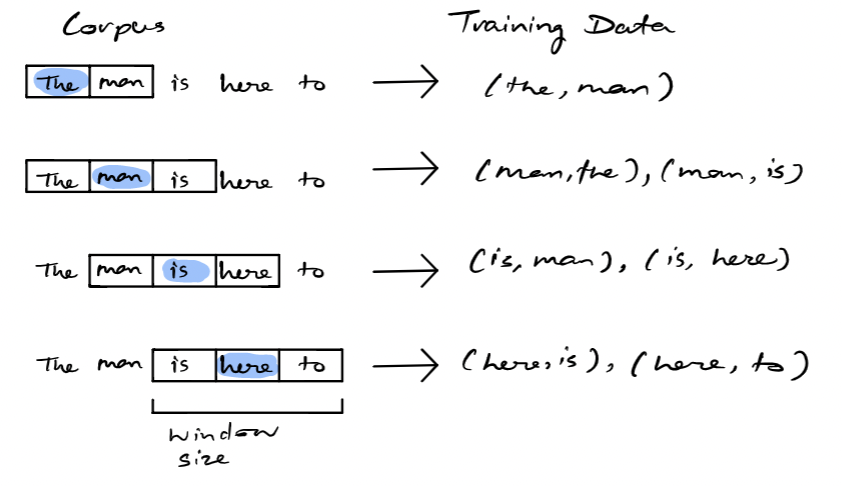
github: https://github.com/pandalabme/d2l/tree/main/exercises 1. How does the running time of code in this section changes if not using subsampling? i
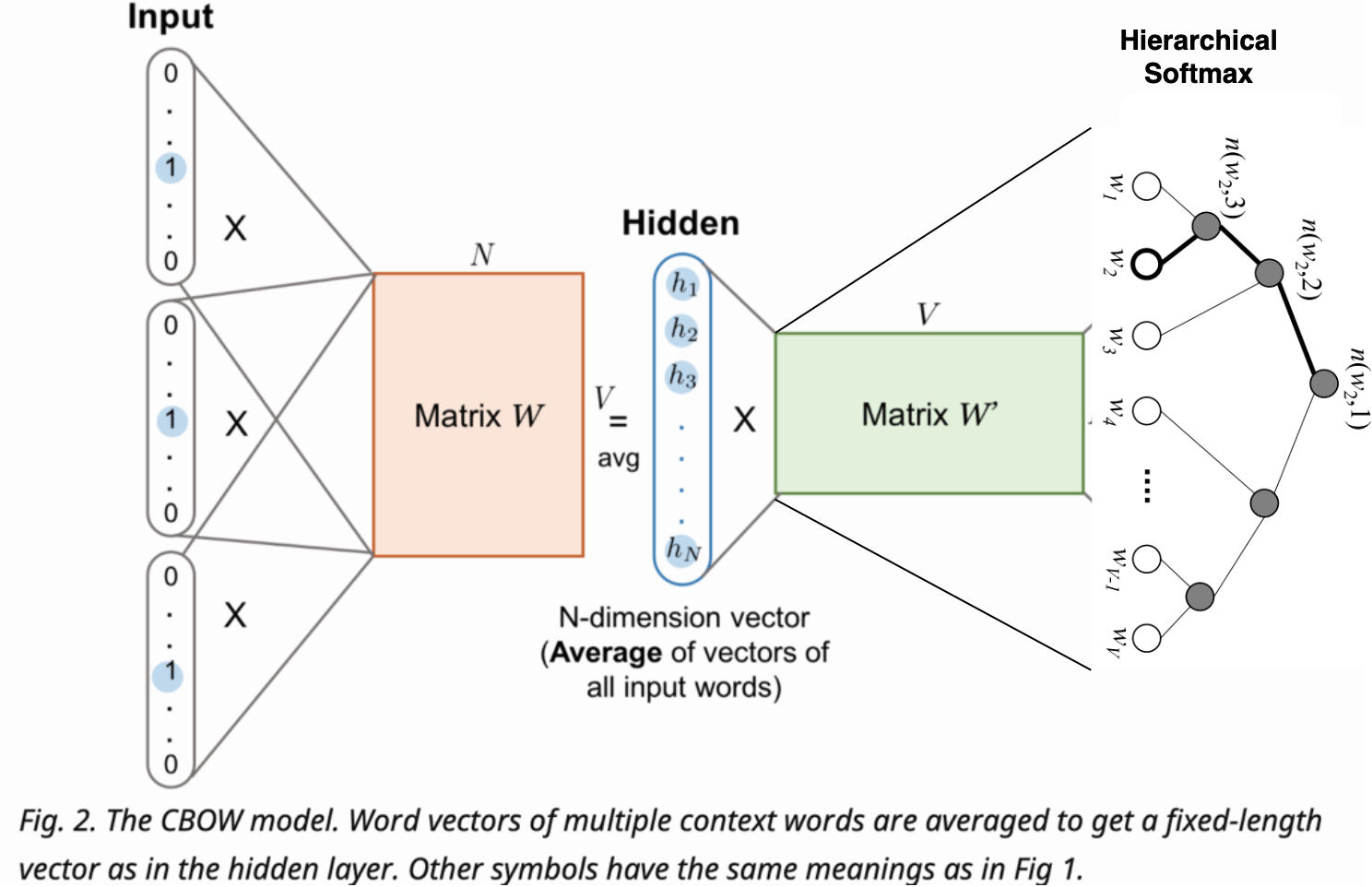
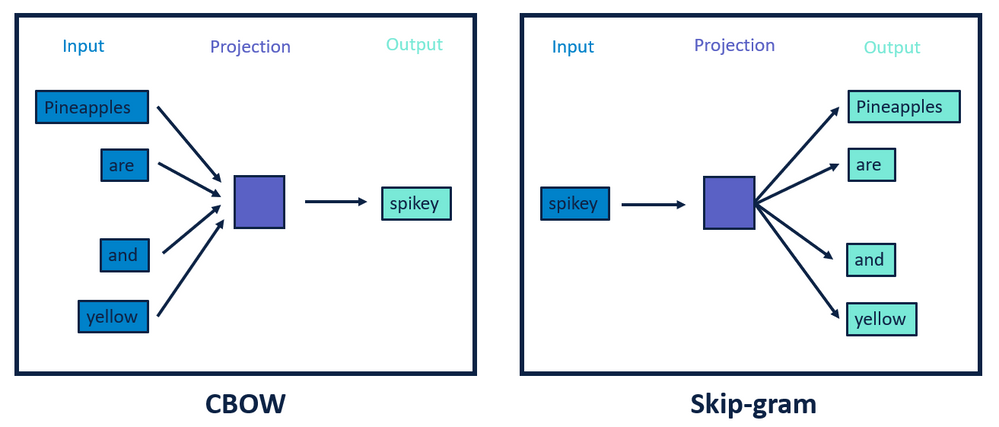
github: https://github.com/pandalabme/d2l/tree/main/exercises 1. How can we sample noise words in negative sampling? Negative sampling is a technique
github: https://github.com/pandalabme/d2l/tree/main/exercises 1. What is the computational complexity for calculating each gradient? What could be the
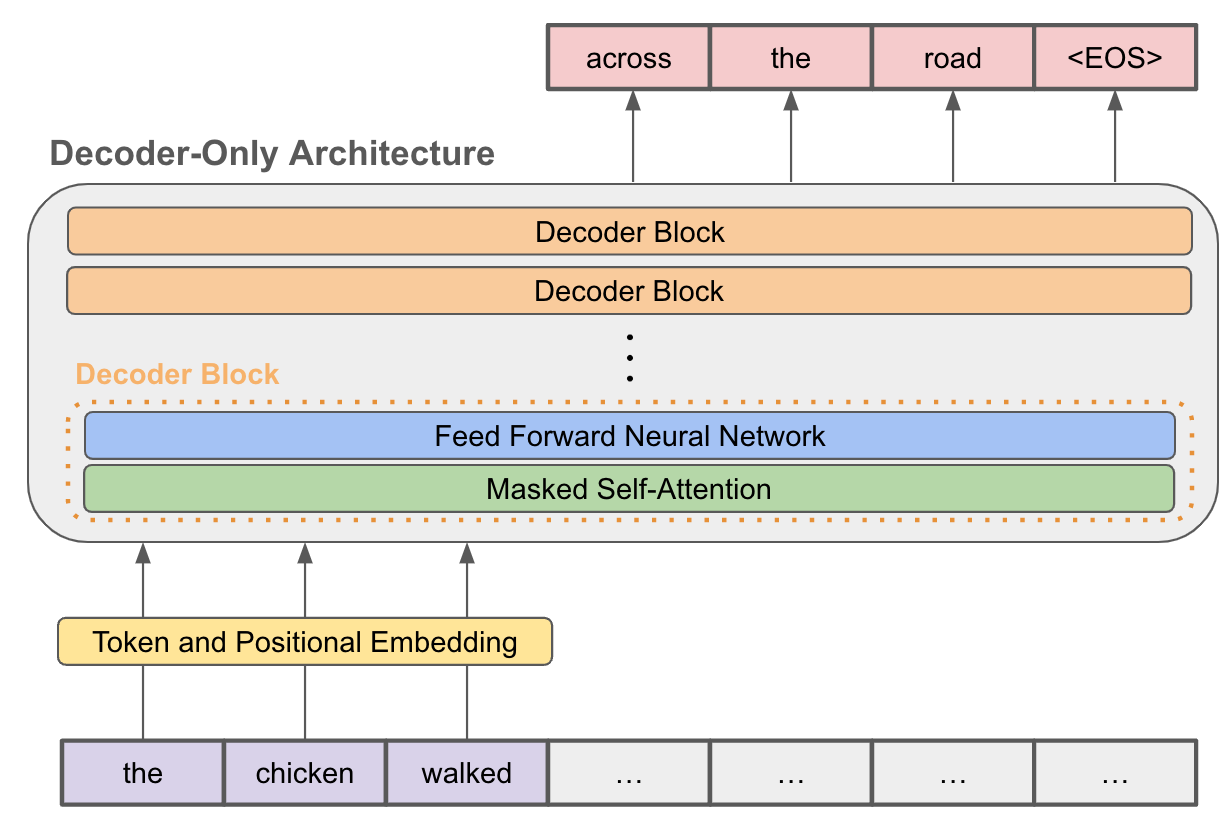
github: https://github.com/pandalabme/d2l/tree/main/exercises 1. Is it possible to fine-tune T5 using a minibatch consisting of different tasks? Why o
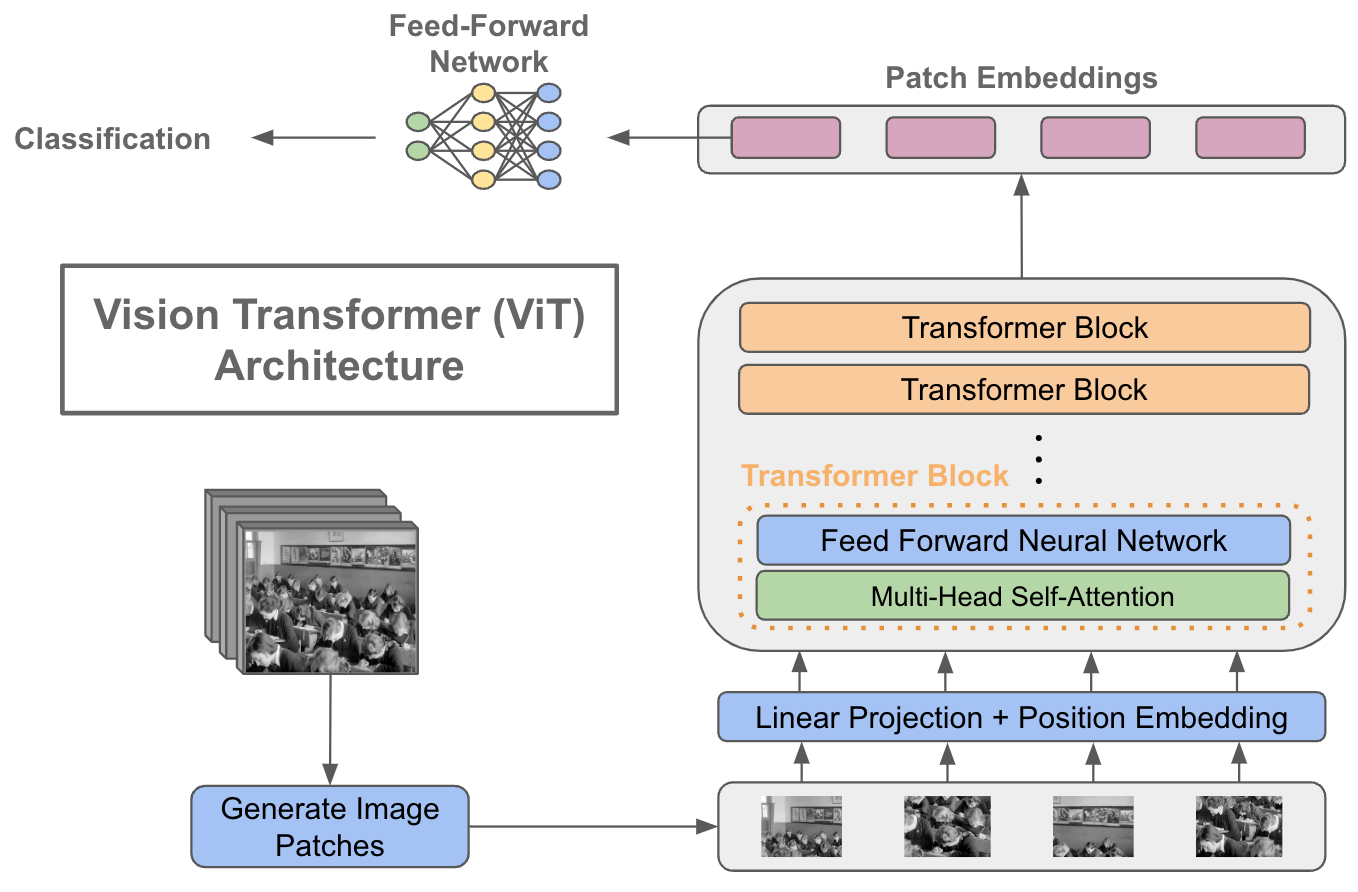
github: https://github.com/pandalabme/d2l/tree/main/exercises 1. How does the value of img_size affect training time? The value of img_size affects th
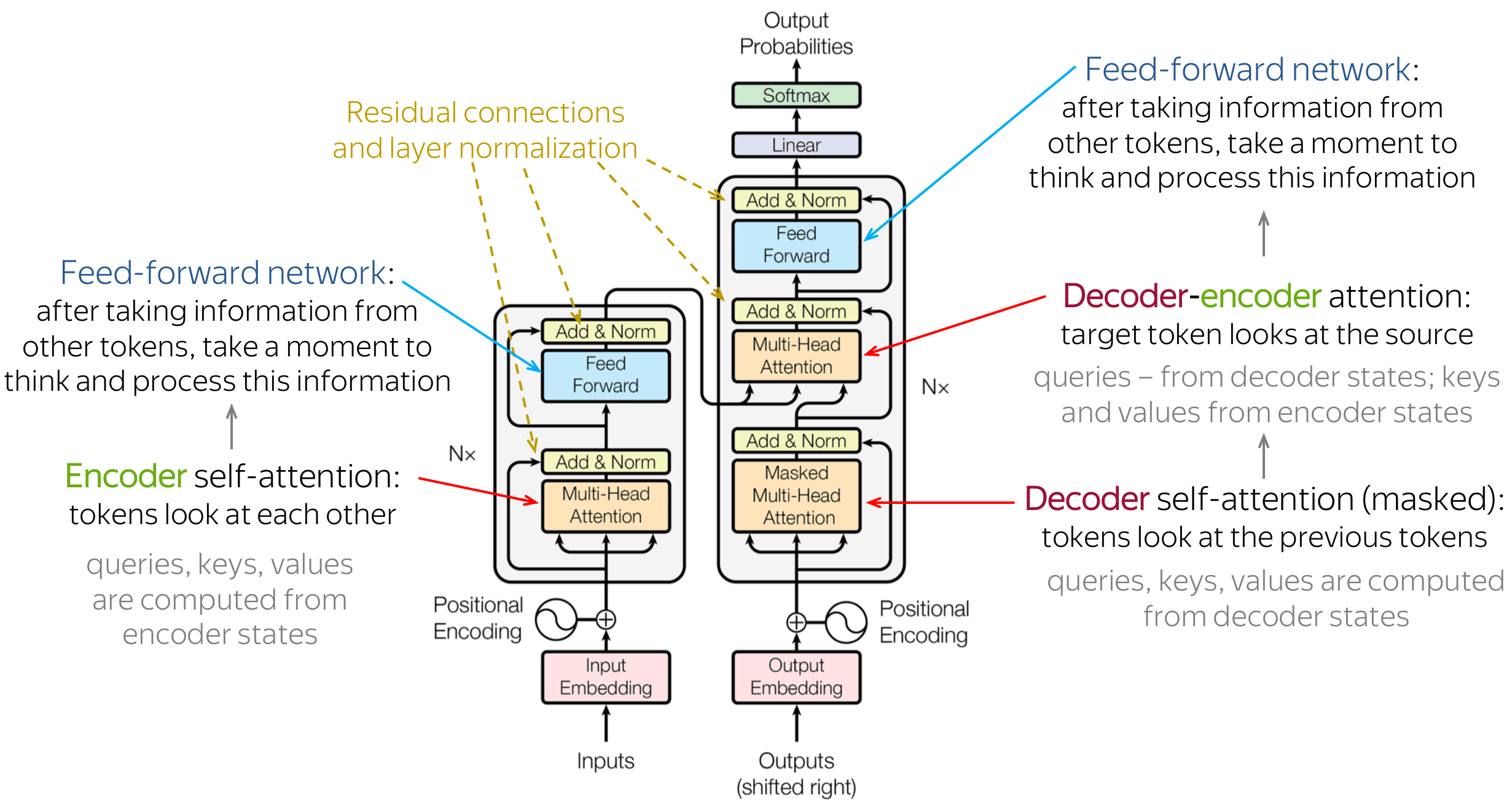
github: https://github.com/pandalabme/d2l/tree/main/exercises 1. Train a deeper Transformer in the experiments. How does it affect the training speed