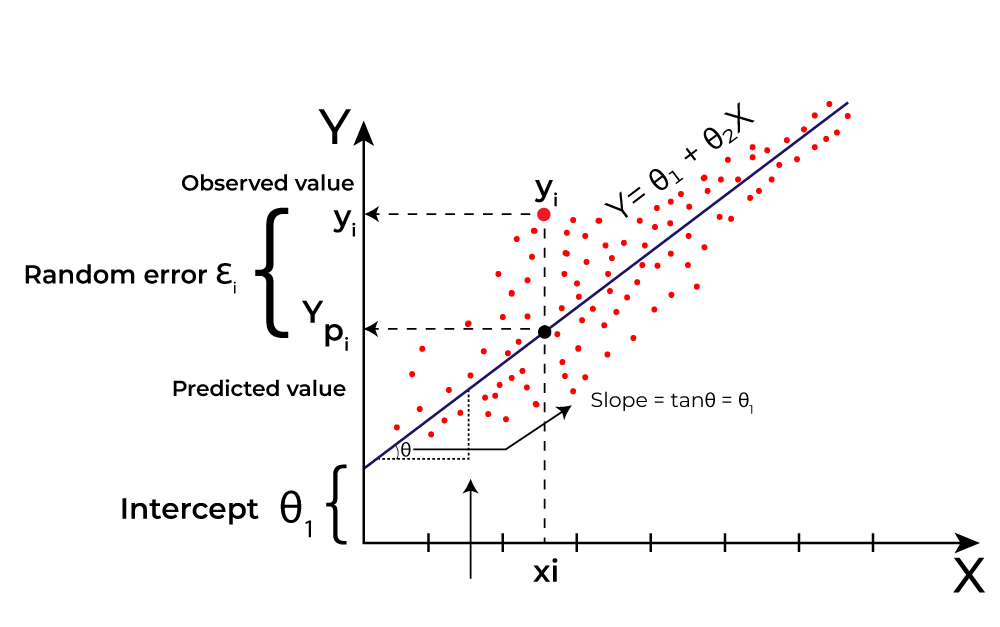
1. Line regression 1.1 Ordinary Least Squares (OLS) Perspective 1.1.1 Model Representation: The linear regression model is represented as: \hat{Y} = X
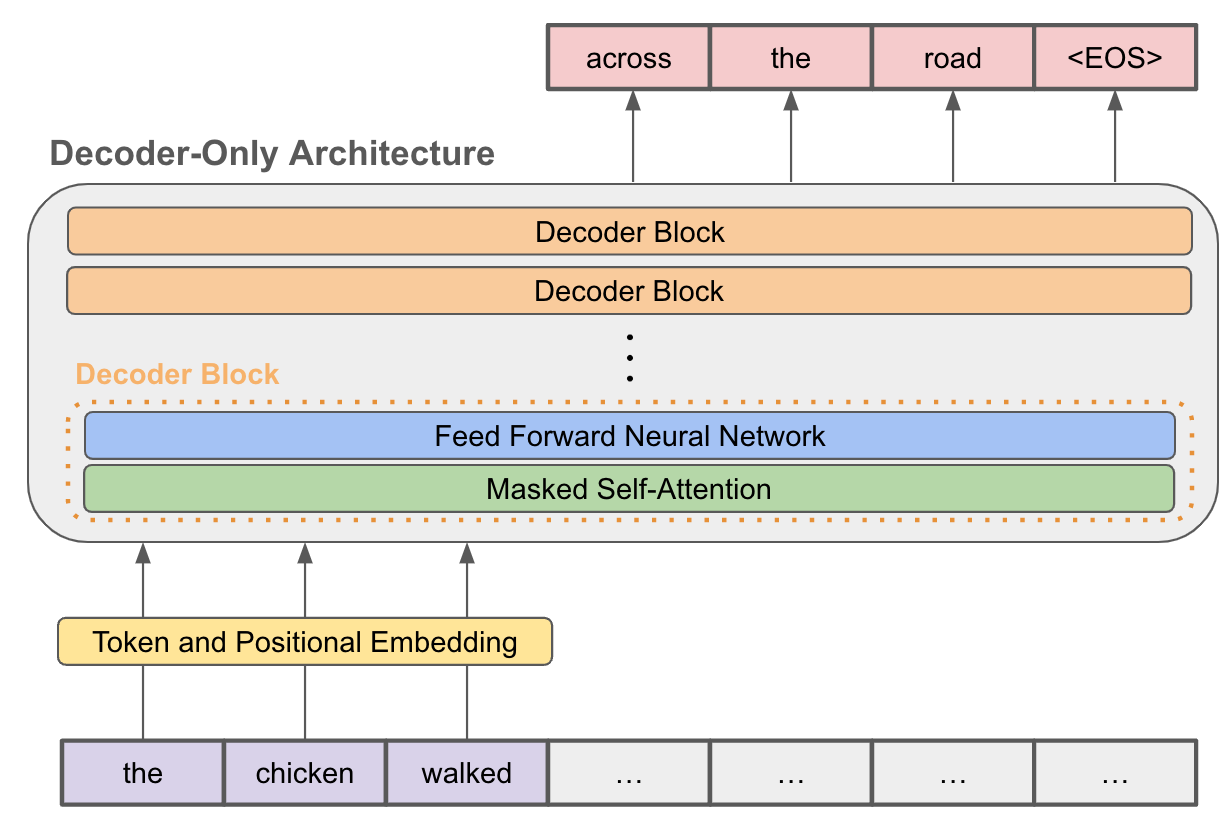
github: https://github.com/pandalabme/d2l/tree/main/exercises 1. Is it possible to fine-tune T5 using a minibatch consisting of different tasks? Why o
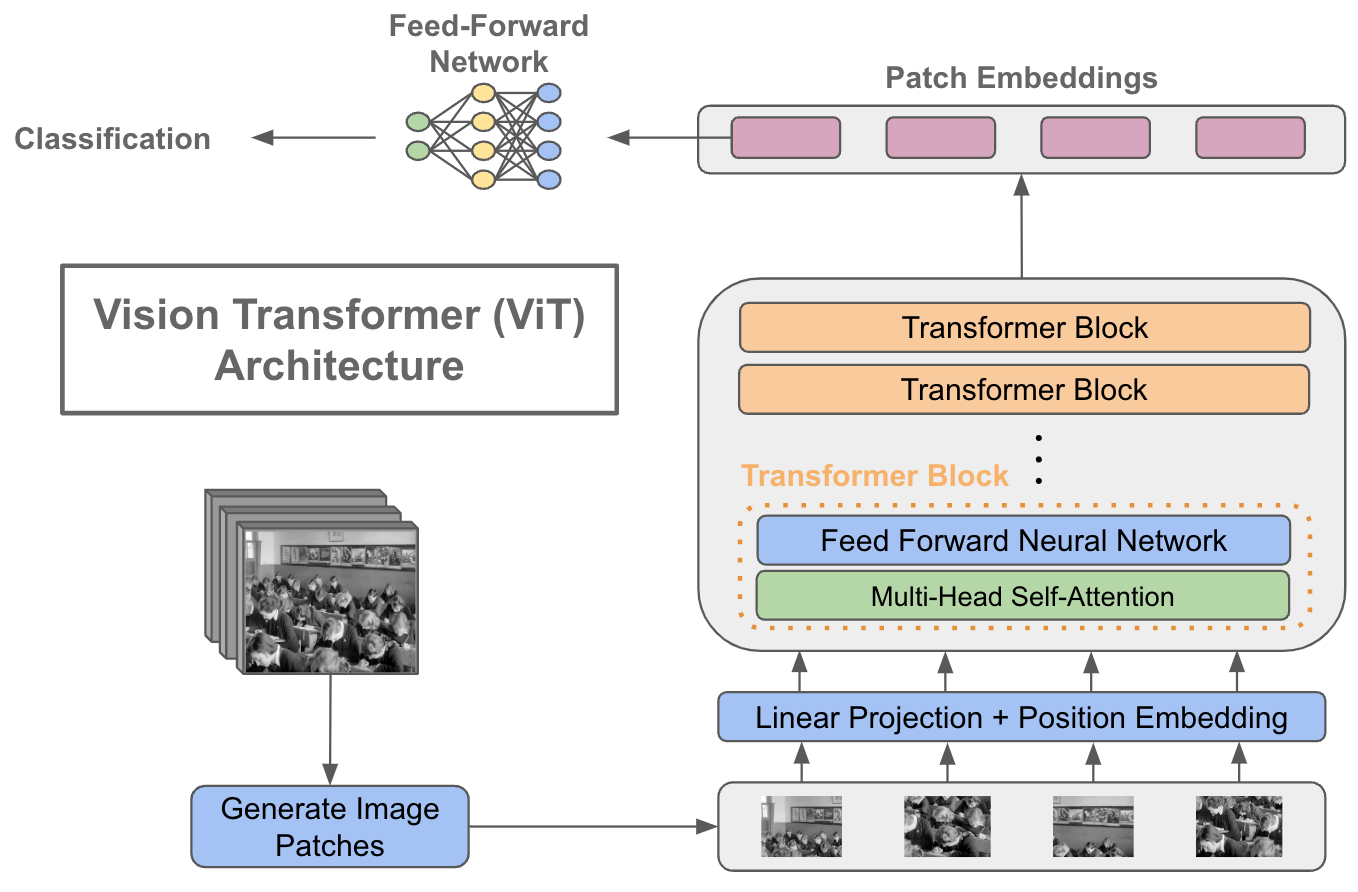
github: https://github.com/pandalabme/d2l/tree/main/exercises 1. How does the value of img_size affect training time? The value of img_size affects th
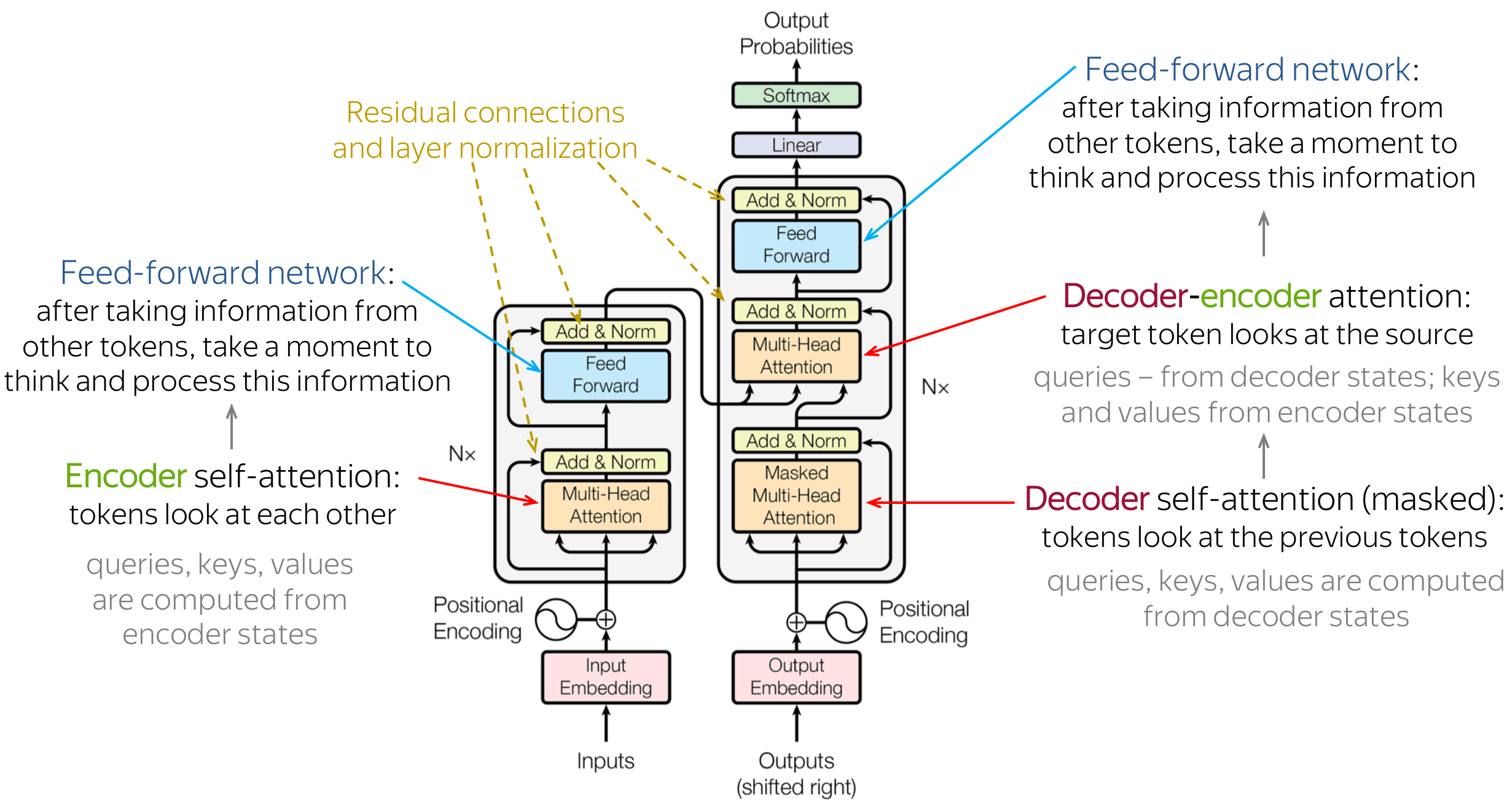
github: https://github.com/pandalabme/d2l/tree/main/exercises 1. Train a deeper Transformer in the experiments. How does it affect the training speed

github: https://github.com/pandalabme/d2l/tree/main/exercises 1. Suppose that we design a deep architecture to represent a sequence by stacking self-a
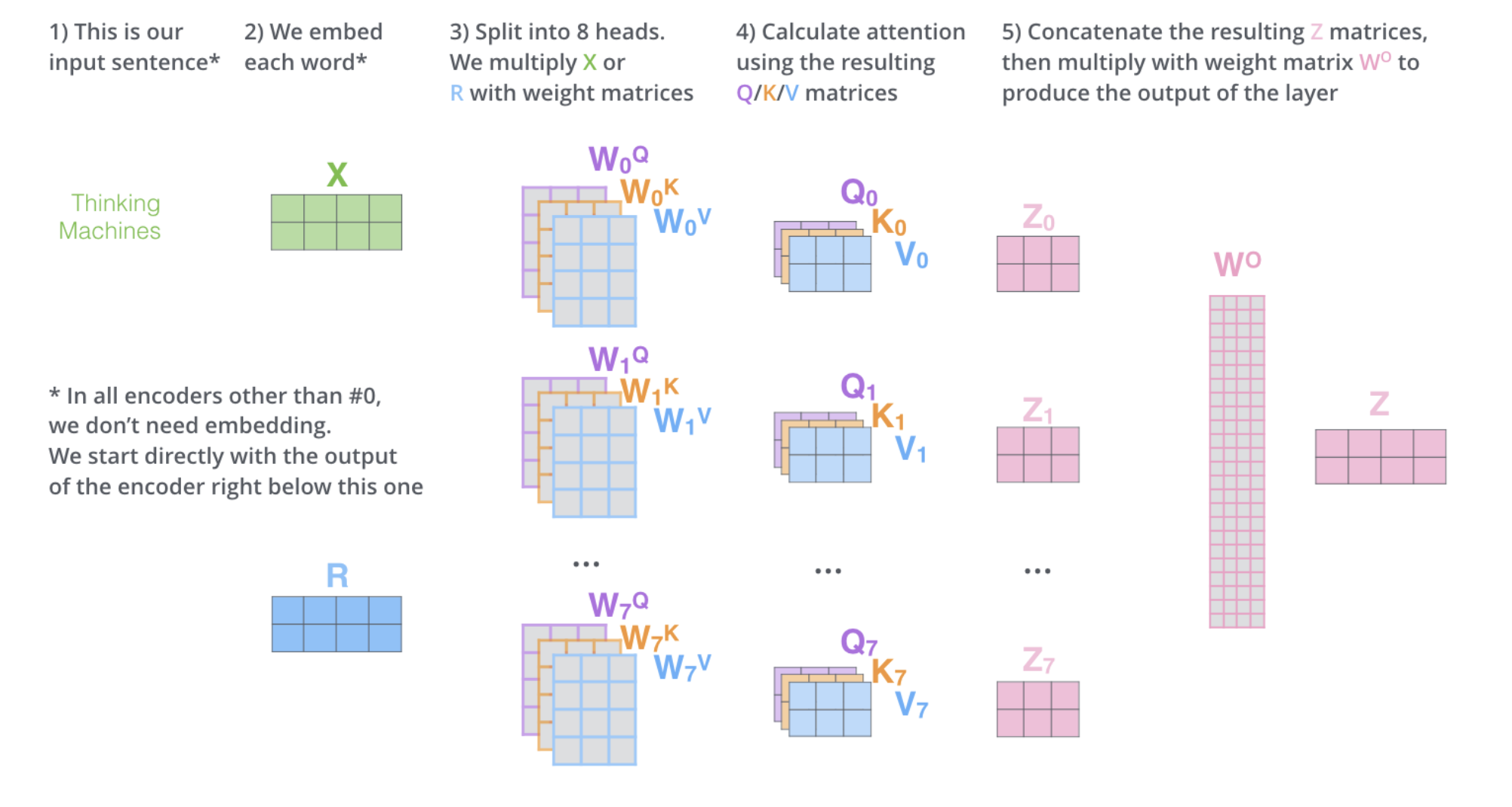
github: https://github.com/pandalabme/d2l/tree/main/exercises 1. Visualize attention weights of multiple heads in this experiment. import sys import t
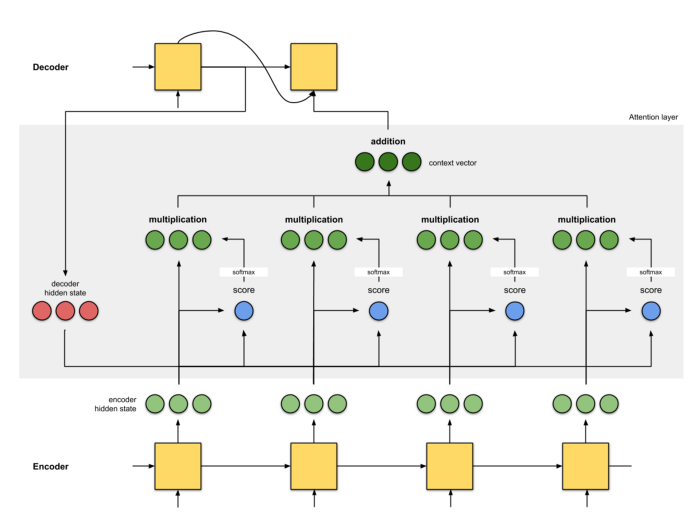
github: https://github.com/pandalabme/d2l/tree/main/exercises 1. Replace GRU with LSTM in the experiment. import sys import torch.nn as nn import torc
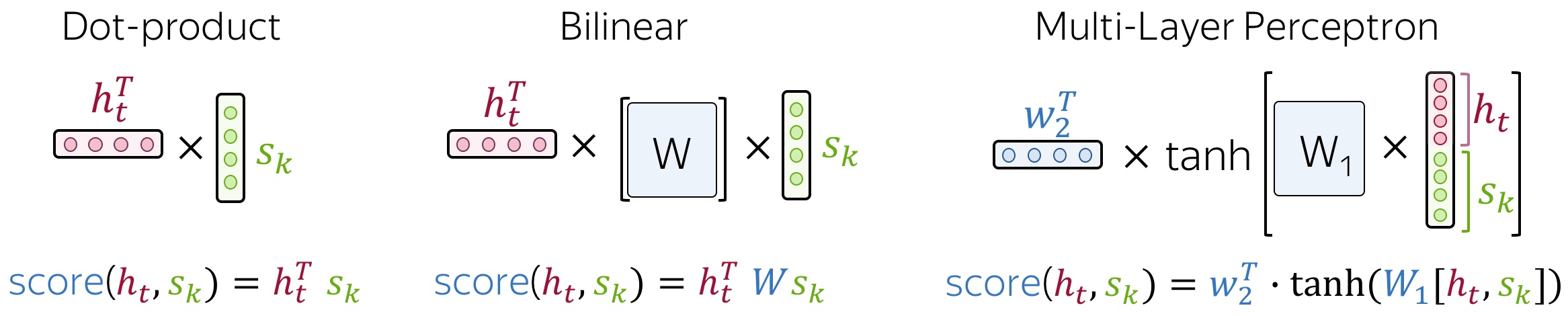
github: https://github.com/pandalabme/d2l/tree/main/exercises 1. Implement distance-based attention by modifying the DotProductAttention code. Note th

github: https://github.com/pandalabme/d2l/tree/main/exercises 1. Parzen windows density estimates are given by \hat{p}(x)=\frac{1}{n}\sum_ik(x,x_i)
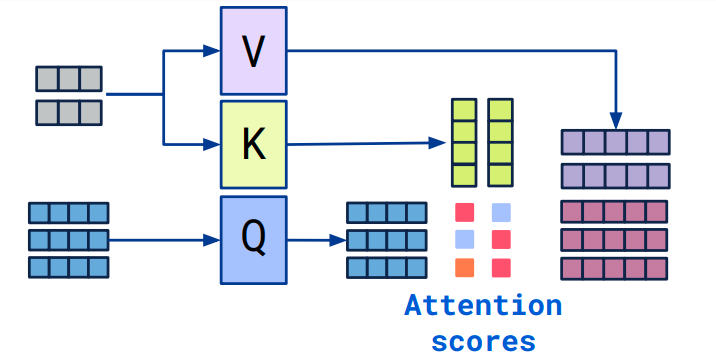
github: https://github.com/pandalabme/d2l/tree/main/exercises import sys import torch.nn as nn import torch import warnings from sklearn.model_selecti
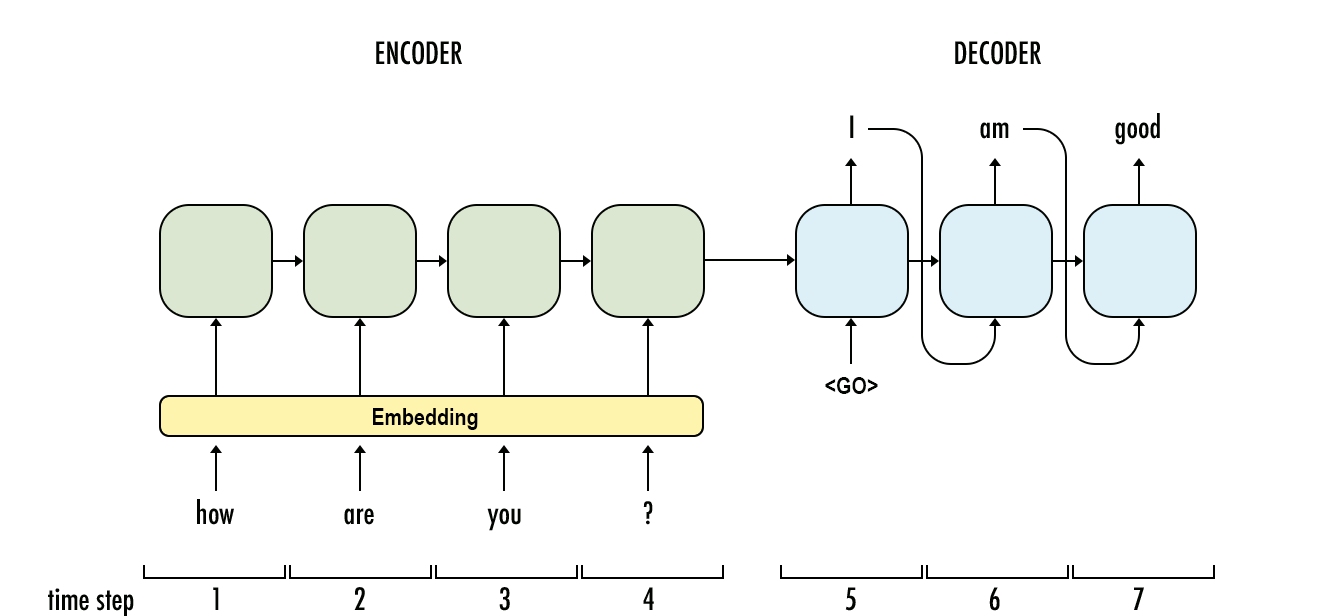
github: https://github.com/pandalabme/d2l/tree/main/exercises import sys import torch.nn as nn import torch import warnings import numpy as np from sk