github:
https://github.com/pandalabme/d2l/tree/main/exercises
import sys
import torch.nn as nn
import torch
import warnings
sys.path.append('/home/jovyan/work/d2l_solutions/notebooks/exercises/d2l_utils/')
import d2l
warnings.filterwarnings("ignore")
1. Let’s modernize LeNet. Implement and test the following changes:
1.1 Replace average pooling with max-pooling.
class MaxPoolingLeNet(d2l.Classifier):
def __init__(self, lr=0.1, num_classes=10):
super().__init__()
self.save_hyperparameters()
self.net = nn.Sequential(nn.LazyConv2d(6, kernel_size=5, padding=2),
nn.Sigmoid(),
nn.MaxPool2d(kernel_size=2, stride=2),
nn.LazyConv2d(16, kernel_size=5),
nn.Sigmoid(),
nn.MaxPool2d(kernel_size=2, stride=2),
nn.Flatten(),
nn.LazyLinear(120),
nn.Sigmoid(),
nn.LazyLinear(84),
nn.Sigmoid(),
nn.LazyLinear(num_classes))
def init_cnn(module):
if type(module) == nn.Linear or type(module) == nn.Conv2d:
nn.init.xavier_uniform_(module.weight)
data = d2l.FashionMNIST(batch_size=256)
model = MaxPoolingLeNet(lr=0.1)
model.apply_init([next(iter(data.get_dataloader(True)))[0]], init_cnn)
trainer = d2l.Trainer(max_epochs=10)
trainer.fit(model, data)
y_hat = model(data.val.data.type(torch.float32).unsqueeze(dim=1))
print(f'acc: {model.accuracy(y_hat,data.val.targets).item():.2f}')
acc: 0.32

1.2 Replace the softmax layer with ReLU.
class ReLULeNet(d2l.Classifier):
def __init__(self, lr=0.1, num_classes=10):
super().__init__()
self.save_hyperparameters()
self.net = nn.Sequential(nn.LazyConv2d(6, kernel_size=5, padding=2),
nn.ReLU(),
nn.MaxPool2d(kernel_size=2, stride=2),
nn.LazyConv2d(16, kernel_size=5),
nn.ReLU(),
nn.MaxPool2d(kernel_size=2, stride=2),
nn.Flatten(),
nn.LazyLinear(120),
nn.ReLU(),
nn.LazyLinear(84),
nn.ReLU(),
nn.LazyLinear(num_classes))
model = ReLULeNet(lr=0.1)
model.apply_init([next(iter(data.get_dataloader(True)))[0]], init_cnn)
trainer = d2l.Trainer(max_epochs=10)
trainer.fit(model, data)
(69.25442786514759, 14.578803978860378)

y_hat = model(data.val.data.type(torch.float32).unsqueeze(dim=1))
print(f'acc: {model.accuracy(y_hat,data.val.targets).item():.2f}')
acc: 0.80
2. Try to change the size of the LeNet style network to improve its accuracy in addition to max-pooling and ReLU.
class ParamLeNet(d2l.Classifier):
def __init__(self, convs, linears, lr=0.1, num_classes=10):
super().__init__()
self.save_hyperparameters()
layers = []
for conv in convs:
layers.append(nn.LazyConv2d(conv[0], kernel_size=conv[1],
padding=conv[2]))
layers.append(nn.ReLU())
layers.append(nn.MaxPool2d(kernel_size=2, stride=2))
layers.append(nn.Flatten())
for linear in linears:
layers.append(nn.LazyLinear(linear))
layers.append(nn.ReLU())
layers.append(nn.LazyLinear(num_classes))
self.net = nn.Sequential(*layers)
2.1 Adjust the convolution window size.
convs_list = [[[6,11,5],[16,11,0]],[[6,5,2],[16,5,0]],[[6,3,1],[16,3,0]]]
acc_list = []
for convs in convs_list:
hparams = {'convs':convs, 'linears':[120,84]}
model = ParamLeNet(**hparams)
model.apply_init([next(iter(data.get_dataloader(True)))[0]], init_cnn)
trainer = d2l.Trainer(max_epochs=10)
trainer.fit(model, data)
y_hat = model(data.val.data.type(torch.float32).unsqueeze(dim=1))
acc_list.append(model.accuracy(y_hat,data.val.targets).item())



d2l.plot(list(range(len(acc_list))),acc_list,'conv window','acc')

2.2 Adjust the number of output channels.
convs_list = [[[16,5,2],[32,5,0]],[[6,5,2],[16,5,0]],[[2,5,2],[8,5,0]]]
acc_list = []
for convs in convs_list:
hparams = {'convs':convs, 'linears':[120,84]}
model = ParamLeNet(**hparams)
model.apply_init([next(iter(data.get_dataloader(True)))[0]], init_cnn)
trainer = d2l.Trainer(max_epochs=10)
trainer.fit(model, data)
y_hat = model(data.val.data.type(torch.float32).unsqueeze(dim=1))
acc_list.append(model.accuracy(y_hat,data.val.targets).item())



d2l.plot(list(range(len(acc_list))),acc_list,'channels','acc')

2.3 Adjust the number of convolution layers.
data = d2l.FashionMNIST(batch_size=256)
convs_list = [[[6,5,2],[16,5,2],[32,5,0]],[[6,5,2],[16,5,0]],[[64,5,0]]]
acc_list = []
for convs in convs_list:
hparams = {'convs':convs, 'linears':[120,84]}
model = ParamLeNet(**hparams)
model.apply_init([next(iter(data.get_dataloader(True)))[0]], init_cnn)
trainer = d2l.Trainer(max_epochs=10)
trainer.fit(model, data)
y_hat = model(data.val.data.type(torch.float32).unsqueeze(dim=1))
acc_list.append(model.accuracy(y_hat,data.val.targets).item())



d2l.plot(list(range(len(acc_list))),acc_list,'conv layers','acc')

2.4 Adjust the number of fully connected layers.
linears_list = [[256,128,64,32,16],[256,128],[120,84],[64,32]]
acc_list = []
for linears in linears_list:
hparams = {'convs':[[6,5,2],[16,5,0]], 'linears':linears}
model = ParamLeNet(**hparams)
model.apply_init([next(iter(data.get_dataloader(True)))[0]], init_cnn)
trainer = d2l.Trainer(max_epochs=10)
trainer.fit(model, data)
y_hat = model(data.val.data.type(torch.float32).unsqueeze(dim=1))
acc_list.append(model.accuracy(y_hat,data.val.targets).item())




d2l.plot(list(range(len(acc_list))),acc_list,'fc','acc')

2.5 Adjust the learning rates and other training details (e.g., initialization and number of epochs).
data = d2l.FashionMNIST(batch_size=256)
lr_list = [0.001,0.003,0.01,0.03,0.1,0.3]
acc_list = []
for lr in lr_list:
hparams = {'convs':[[6,5,2],[16,5,0]], 'linears':[120,84],'lr':lr}
model = ParamLeNet(**hparams)
model.apply_init([next(iter(data.get_dataloader(True)))[0]], init_cnn)
trainer = d2l.Trainer(max_epochs=10)
trainer.fit(model, data)
y_hat = model(data.val.data.type(torch.float32).unsqueeze(dim=1))
acc_list.append(model.accuracy(y_hat,data.val.targets).item())






d2l.plot(list(range(len(acc_list))),acc_list,'lr','acc')

3. Try out the improved network on the original MNIST dataset.
hparams = {'convs':[[16,5,2],[32,5,0]], 'linears':[64,32]}
model = ParamLeNet(**hparams)
model.apply_init([next(iter(data.get_dataloader(True)))[0]], init_cnn)
trainer = d2l.Trainer(max_epochs=10)
trainer.fit(model, data)
y_hat = model(data.val.data.type(torch.float32).unsqueeze(dim=1))
model.accuracy(y_hat,data.val.targets).item()
0.8565999865531921

4. Display the activations of the first and second layer of LeNet for different inputs (e.g., sweaters and coats).
data = d2l.FashionMNIST(batch_size=256)
hparams = {'convs':[[16,5,2],[32,5,0]], 'linears':[64,32]}
model = ParamLeNet(**hparams)
model.apply_init([next(iter(data.get_dataloader(True)))[0]], init_cnn)
trainer = d2l.Trainer(max_epochs=10,plot_flag=False)
trainer.fit(model, data)
(69.45040786266327, 14.2749924659729)
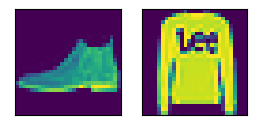
pic = data.val.data[:2,:].type(torch.float32).unsqueeze(dim=1)
d2l.show_images(pic.squeeze(),1,2)
array([<AxesSubplot:>, <AxesSubplot:>], dtype=object)
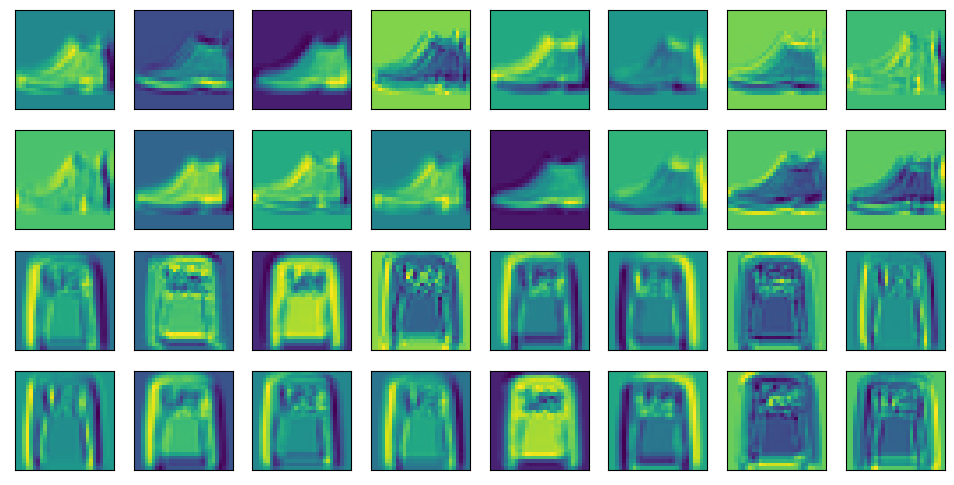
d2l.show_images(model.net[0](pic).squeeze().detach().numpy().reshape(-1,28,28),4,8)
array([<AxesSubplot:>, <AxesSubplot:>, <AxesSubplot:>, <AxesSubplot:>,
<AxesSubplot:>, <AxesSubplot:>, <AxesSubplot:>, <AxesSubplot:>,
<AxesSubplot:>, <AxesSubplot:>, <AxesSubplot:>, <AxesSubplot:>,
<AxesSubplot:>, <AxesSubplot:>, <AxesSubplot:>, <AxesSubplot:>,
<AxesSubplot:>, <AxesSubplot:>, <AxesSubplot:>, <AxesSubplot:>,
<AxesSubplot:>, <AxesSubplot:>, <AxesSubplot:>, <AxesSubplot:>,
<AxesSubplot:>, <AxesSubplot:>, <AxesSubplot:>, <AxesSubplot:>,
<AxesSubplot:>, <AxesSubplot:>, <AxesSubplot:>, <AxesSubplot:>],
dtype=object)
d2l.show_images(model.net[:2](pic).squeeze().detach().numpy().reshape(-1,28,28),4,8)
array([<AxesSubplot:>, <AxesSubplot:>, <AxesSubplot:>, <AxesSubplot:>,
<AxesSubplot:>, <AxesSubplot:>, <AxesSubplot:>, <AxesSubplot:>,
<AxesSubplot:>, <AxesSubplot:>, <AxesSubplot:>, <AxesSubplot:>,
<AxesSubplot:>, <AxesSubplot:>, <AxesSubplot:>, <AxesSubplot:>,
<AxesSubplot:>, <AxesSubplot:>, <AxesSubplot:>, <AxesSubplot:>,
<AxesSubplot:>, <AxesSubplot:>, <AxesSubplot:>, <AxesSubplot:>,
<AxesSubplot:>, <AxesSubplot:>, <AxesSubplot:>, <AxesSubplot:>,
<AxesSubplot:>, <AxesSubplot:>, <AxesSubplot:>, <AxesSubplot:>],
dtype=object)
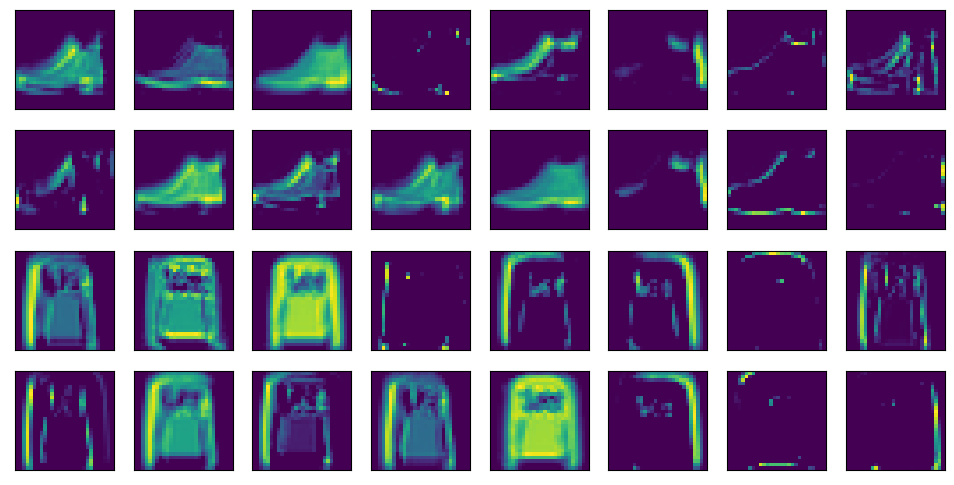
5. What happens to the activations when you feed significantly different images into the network (e.g., cats, cars, or even random noise)?
import torchvision
from torchvision import transforms
trans = transforms.Compose([transforms.Resize((28, 28)),
transforms.ToTensor()])
data = torchvision.datasets.MNIST(root='../data',train=True, transform=trans, download=True)
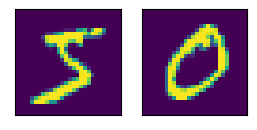
pic = data.data[:2,:].type(torch.float32).unsqueeze(dim=1)
d2l.show_images(pic.squeeze(),1,2)
array([<AxesSubplot:>, <AxesSubplot:>], dtype=object)
d2l.show_images(model.net[0](pic).squeeze().detach().numpy().reshape(-1,28,28),4,8)
array([<AxesSubplot:>, <AxesSubplot:>, <AxesSubplot:>, <AxesSubplot:>,
<AxesSubplot:>, <AxesSubplot:>, <AxesSubplot:>, <AxesSubplot:>,
<AxesSubplot:>, <AxesSubplot:>, <AxesSubplot:>, <AxesSubplot:>,
<AxesSubplot:>, <AxesSubplot:>, <AxesSubplot:>, <AxesSubplot:>,
<AxesSubplot:>, <AxesSubplot:>, <AxesSubplot:>, <AxesSubplot:>,
<AxesSubplot:>, <AxesSubplot:>, <AxesSubplot:>, <AxesSubplot:>,
<AxesSubplot:>, <AxesSubplot:>, <AxesSubplot:>, <AxesSubplot:>,
<AxesSubplot:>, <AxesSubplot:>, <AxesSubplot:>, <AxesSubplot:>],
dtype=object)

d2l.show_images(model.net[:2](pic).squeeze().detach().numpy().reshape(-1,28,28),4,8)
array([<AxesSubplot:>, <AxesSubplot:>, <AxesSubplot:>, <AxesSubplot:>,
<AxesSubplot:>, <AxesSubplot:>, <AxesSubplot:>, <AxesSubplot:>,
<AxesSubplot:>, <AxesSubplot:>, <AxesSubplot:>, <AxesSubplot:>,
<AxesSubplot:>, <AxesSubplot:>, <AxesSubplot:>, <AxesSubplot:>,
<AxesSubplot:>, <AxesSubplot:>, <AxesSubplot:>, <AxesSubplot:>,
<AxesSubplot:>, <AxesSubplot:>, <AxesSubplot:>, <AxesSubplot:>,
<AxesSubplot:>, <AxesSubplot:>, <AxesSubplot:>, <AxesSubplot:>,
<AxesSubplot:>, <AxesSubplot:>, <AxesSubplot:>, <AxesSubplot:>],
dtype=object)
